Extract File Data
Extract structured data from documents and images using AI-powered processing. This endpoint supports multiple upload methods and provides flexible configuration options for data extraction.
POST /extract-file-data
Overview
The Extract File Data endpoint processes your documents and returns a job ID for tracking the extraction progress. You can specify exactly what data fields you need, provide custom instructions, and choose from multiple upload methods.
- Be specific about the data you need - this improves accuracy
- Use descriptive column names that match your document structure
- Include extraction instructions for complex or unusual document layouts
- Test in Lido first - Use the Data Extractor in Lido app to fine-tune your settings, then click the API button to get the exact configuration
Configure in Lido, Then Use the API
The easiest way to get your API configuration perfect is to use the Data Extractor in the Lido app first:
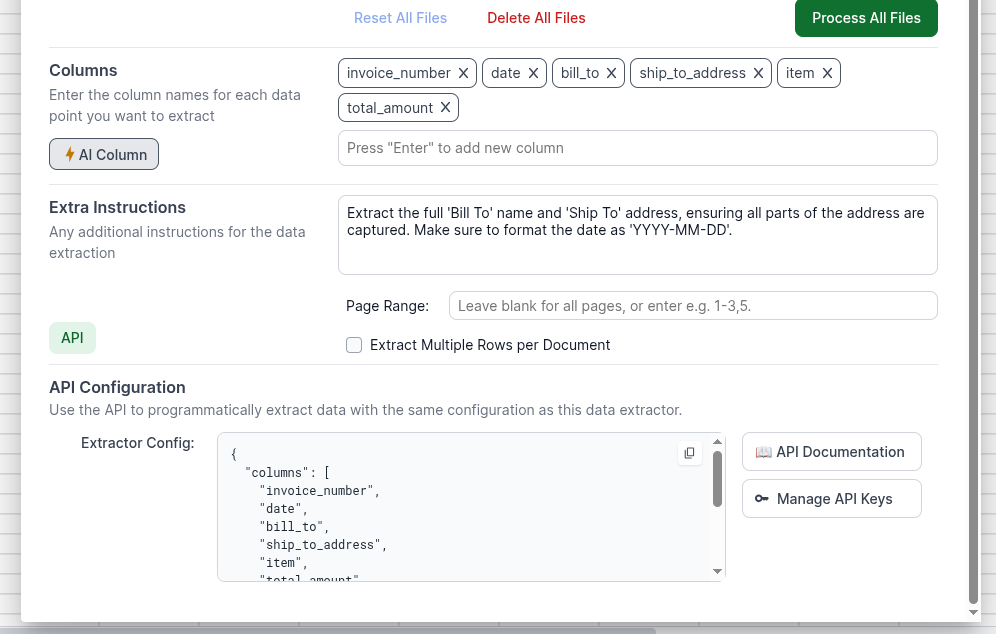
Step-by-Step Configuration
- Open the Data Extractor in your Lido workspace
- Upload your test document and configure your extraction settings:
- Add the column names you want to extract
- Write any special instructions for the AI
- Set page ranges if needed
- Toggle multi-row extraction if your data spans multiple rows
- Test the extraction to ensure it works correctly
- Click the API button in the bottom left corner of the Data Extractor
- Copy the generated configuration - this gives you the exact JSON structure to use in your API calls
This workflow ensures your API integration will work exactly as expected, since you've already tested and validated the extraction settings in the Lido app.
For more detailed guidance on using the PDF Data Extractor, see our help documentation.
Upload Methods
Choose the upload method that best fits your application:
Method 1: JSON with Base64 Encoding
Perfect for web applications and smaller files (up to 50MB).
Method 2: Multipart Form Data
Ideal for larger files (up to 500MB) and server-side integrations.
JSON Base64 Upload
Upload files encoded as base64 strings within a JSON payload.
Request Details
Content-Type: application/json
Max File Size: 50MB
Rate Limit: 5 requests per 30 seconds
Request Body
| Parameter | Type | Required | Description |
|---|---|---|---|
file | object | ✅ | File information object |
file.type | string | ✅ | Must be "base64" |
file.data | string | ✅ | Base64 encoded file content |
file.name | string | ❌ | Original filename (e.g., "invoice.pdf") |
columns | array | ✅ | List of data fields to extract |
instructions | string | ❌ | Additional extraction guidance |
multiRow | boolean | ❌ | Set to true for tabular data (default: false) |
pageRange | string | ❌ | Page range to process (e.g., "1-3", "2", "1,3,5") |
Examples
- JavaScript
- Python
- cURL
const fs = require('fs');
const url = "https://sheets.lido.app/api/v1/extract-file-data";
const headers = {
Authorization: "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
};
// Read and encode file
const fileBase64 = fs.readFileSync("invoice.pdf").toString("base64");
const payload = {
file: {
type: "base64",
data: fileBase64,
name: "invoice.pdf"
},
columns: ["Vendor Name", "Invoice Number", "Total Amount", "Due Date"],
instructions: "Extract the main vendor information and financial details. Ensure amounts include currency symbols.",
multiRow: false,
pageRange: "1"
};
try {
const response = await fetch(url, {
method: "POST",
headers,
body: JSON.stringify(payload)
});
const result = await response.json();
console.log("Job ID:", result.jobId);
} catch (error) {
console.error("Error:", error);
}
import requests
import base64
url = "https://sheets.lido.app/api/v1/extract-file-data"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
# Read and encode file
with open("invoice.pdf", "rb") as file:
file_base64 = base64.b64encode(file.read()).decode("utf-8")
payload = {
"file": {
"type": "base64",
"data": file_base64,
"name": "invoice.pdf"
},
"columns": ["Vendor Name", "Invoice Number", "Total Amount", "Due Date"],
"instructions": "Extract the main vendor information and financial details. Ensure amounts include currency symbols.",
"multiRow": False,
"pageRange": "1"
}
try:
response = requests.post(url, headers=headers, json=payload)
result = response.json()
print(f"Job ID: {result['jobId']}")
except Exception as error:
print(f"Error: {error}")
curl --request POST \
--url 'https://sheets.lido.app/api/v1/extract-file-data' \
--header 'Authorization: Bearer YOUR_API_KEY' \
--header 'Content-Type: application/json' \
--data '{
"file": {
"type": "base64",
"data": "'$(base64 -w 0 invoice.pdf)'",
"name": "invoice.pdf"
},
"columns": ["Vendor Name", "Invoice Number", "Total Amount", "Due Date"],
"instructions": "Extract the main vendor information and financial details. Ensure amounts include currency symbols.",
"multiRow": false,
"pageRange": "1"
}'
Multipart Form Data Upload
Upload files directly using multipart/form-data encoding, ideal for larger files.
Request Details
Content-Type: multipart/form-data
Max File Size: 500MB
Rate Limit: 5 requests per 30 seconds
Form Fields
| Field | Type | Required | Description |
|---|---|---|---|
file | file | ✅ | The document file to process |
config | string | ✅ | JSON string with extraction configuration |
Configuration Object
The config field should contain a JSON string with these properties:
| Parameter | Type | Required | Description |
|---|---|---|---|
columns | array | ✅ | List of data fields to extract |
instructions | string | ❌ | Additional extraction guidance |
multiRow | boolean | ❌ | Set to true for tabular data (default: false) |
pageRange | string | ❌ | Page range to process (e.g., "1-3") |
Examples
- JavaScript
- Python
- cURL
const FormData = require('form-data');
const fs = require('fs');
const url = "https://sheets.lido.app/api/v1/extract-file-data";
const headers = { Authorization: "Bearer YOUR_API_KEY" };
const formData = new FormData();
formData.append("file", fs.createReadStream("financial-report.pdf"));
formData.append("config", JSON.stringify({
columns: ["Account Name", "Debit Amount", "Credit Amount", "Balance"],
instructions: "Extract all account balances from the financial statement. Preserve original number formatting including commas and decimal places.",
multiRow: true,
pageRange: "2-5"
}));
try {
const response = await fetch(url, {
method: "POST",
headers,
body: formData
});
const result = await response.json();
console.log("Job ID:", result.jobId);
} catch (error) {
console.error("Error:", error);
}
import requests
import json
url = "https://sheets.lido.app/api/v1/extract-file-data"
headers = {"Authorization": "Bearer YOUR_API_KEY"}
config = {
"columns": ["Account Name", "Debit Amount", "Credit Amount", "Balance"],
"instructions": "Extract all account balances from the financial statement. Preserve original number formatting including commas and decimal places.",
"multiRow": True,
"pageRange": "2-5"
}
files = {
"file": open("financial-report.pdf", "rb"),
"config": (None, json.dumps(config), "application/json")
}
try:
response = requests.post(url, headers=headers, files=files)
result = response.json()
print(f"Job ID: {result['jobId']}")
except Exception as error:
print(f"Error: {error}")
finally:
files["file"].close()
curl --request POST \
--url 'https://sheets.lido.app/api/v1/extract-file-data' \
--header 'Authorization: Bearer YOUR_API_KEY' \
--form 'file=@financial-report.pdf' \
--form 'config={
"columns": ["Account Name", "Debit Amount", "Credit Amount", "Balance"],
"instructions": "Extract all account balances from the financial statement. Preserve original number formatting including commas and decimal places.",
"multiRow": true,
"pageRange": "2-5"
}'
Response
Both upload methods return the same response format:
{
"status": "running",
"jobId": "c37e0a3b-0bd7-44d0-be7a-3cd1e2a70837"
}
Response Fields
| Field | Type | Description |
|---|---|---|
status | string | Current job status (always "running" for new jobs) |
jobId | string | Unique identifier for tracking your extraction job |
Next Steps
After receiving your job ID:
- Wait for Processing - Allow 10-30 seconds for document processing
- Check Status - Use the Job Result endpoint to check progress
- Retrieve Data - Once complete, get your extracted data from the same endpoint
Job results are stored for 24 hours. Make sure to retrieve your data within this timeframe.
Best Practices
Column Names
- Use descriptive, specific names: "Invoice Total" instead of "Amount"
- Match the terminology used in your documents
- Be consistent across similar document types
Instructions
- Provide context about document layout or unusual formatting
- Specify number formats, date formats, or units when relevant
- Mention any data validation requirements